Best Reverser Write-Up: Analyzing Uncommon Firmware
6/29/2015
While developing tasks for PHDays’ contest in reverse engineering, we had a purpose of replicating real problems that RE specialists might face. At the same time we tried to avoid allowing cliche solutions.
Let us define what common reverse engineering tasks look like. Given an executable file for Windows (or Linux, MacOS or any other widely-used operating system). We can run it, watch it in a debugger, and twist it in virtual environments in any way possible. File format is known. The processor’s instruction set is x86, AMD64 or ARM. Library functions and system calls are documented. The equipment can be accessed through the operating system only. Using tools like IDAPro and HеxRays makes analysis of such applications very simple, while debug protection, virtual machines with their own instruction sets, and obfuscation could complicate the task. But large vendors hardly ever use any of those in their programs. So there’s no point in developing a contest aimed at demonstrating skills that are rarely addressed in practice.
However, there’s another area, where reverse engineering became more in-demand, that’s firmware analysis. The input file (firmware) could be presented in any format, can be packed, encrypted. The operating system could be unpopular, or there could be no operating system at all. Parts of the code could not be changed with firmware updates. The processor could be based on any architecture. (For example, IDAPro “knows” not more than 100 different processors.) And of course, there’s no documentation available, debugging or code execution cannot be performed―a firmware is presented, but there’s no device.
Конечно, иногда для усложнения задачи в программу добавляют виртуальные машины со своим набором инструкций, замусоривание кода, защиту от отладки и т. п. Но если говорить честно — насколько часто крупные производители ПО используют все это в своих исполняемых файлах? Да почти никогда! Какой же смысл делать конкурс, нацеленный на демонстрацию навыков, которые редко требуются в реальной жизни?
Our contest’s participants needed to analyze an executable file and find the correct key and the relative email (any internet user was able to take part in the contest).
Part One: Loader
At the first stage, the input file is an ELF file compiled with a cross compiler for the PA-RISC architecture. IDA can work with this architecture, but not as good as with x86. Most requests to stack variables are not identified automatically, and you’ll have to do it manually. At least you can see all the library functions (log, printf, memcpy, strlen, fprintf, sscanf, memset, strspn) and even symbolic names for some functions (с32, exk, cry, pad, dec, cen, dde). The program expects two input arguments: an email and key.

It’s not hard to figure out that the key should consist of two parts separated by the “-“ character. The first part should consist of seven MIME64 characters (0-9A-Za-z+/), the second part of 32 hex characters that translate to 16 bytes.

Further we can see calls to c32 functions that result in:
t = c32(-1, argv[1], strlen(argv[1])+1) k = ~c32(t, argv[2], strlen(argv[2])+1)
Name of the function is a hint: it’s a СRC32 function, which is confirmed by the constant 0xEDB88320. Next, we call the dde function (short for doDecrypt), and it receives the inverted output of the CRC32 function (encryption key) as the first argument, and the address and the size of the encrypted array as the second and third ones.
Decryption is performed by BTEA (block tiny encryption algorithm) based on the code taken from Wikipedia. We can guess that it’s BTEA from the use of the constant DELTA==0x9E3779B9. It’s also used in other algorithms on which BTEA is based on, but there are not many of them.
The key should be of 128-bit width, but we receive only 32 bits from CRC32. So we get three more DWORDs from the exk function (expand_key) by multiplying the previous value by the same DELTA.
However, the use of BTEA is uncommon. First of all, the algorithm supports a variable-width block size, and we use a block of 12-bytes width (there are processors that have 24-bit width registers and memory, then why should we use only powers of two). And in the second place, we switched encryption and decryption functions.
Since data stream is encrypted, cipher block chaining is applied. Enthropy is calculated for decrypted data in the cen function (calc_enthropy). If its value exceeds 7, the decryption result is considered incorrect and the program will exit.
The encryption key is 32-bit width, so it seems to be easily brute-forced. However, in order to check every key we need to decrypt 80 kilobytes of data, and then calculate enthropy. So brute-forcing the encryption key will take a lot of time.
But after the calculation, we call the pad function (strip_pad), which check and remove PKCS#7 padding. Due to CBC features, we need to decrypt only one block (the last one), extract N byte, check whether its range is between 1 and 12 (inclusive) and each of the last N bytes has value N. This allows reducing the number of operations needed to check one key. But if the last encrypted byte equals 1 (which is true for 1/256 keys), the check should be still performed.
The faster method is to assume that decoded data have a DWORD-aligned length (4 bytes). Then in the last DWORD of the last block there may be only one of three possible values: 0x04040404, 0x08080808 or 0x0C0C0C0C. By using heuristic and brute force methods you can run through all possible keys and find the right one in less than 20 minutes.
If all the checks after the decryption (entropy and the integrity of the padding) are successful, we call the fire_second_proc function, which simulates the launch of the second CPU and the loading of decrypted data of the firmware (modern devices usually have more than one processor—with different architectures).
If the second processor launches, it receives the user’s email and 16 bytes with the second part of the key via the function send_auth_data. At this point we made a mistake: there was the size of the string with the email instead of the size of the second part of the key.
Если второй процессор удалось успешно запустить, ему через функцию send_auth_data передается email пользователя и 16 байт со второй частью ключа. В этом месте мы случайно допустили ошибку: вместо размера второй части ключа использовался размер строки с email.
Part Two: Firmware
The analysis of the second part is a little bit more complicated. There was no ELF file, only a memory image—without headings, function names, and other metadata. Type of the processor and load address were unknown as well.
We thought of brute force as the algorithm of determining the processor architecture. Open in IDA, set the following type, and repeat until IDA shows something similar to a code. The brute force should lead to the conclusion that it is big-endian SPARC.
Now we need to determine the load address. The function 0x22E0 is not called, but it contains a lot of code. We can assume that is the entry point of the program, the start function.
In the third instruction of the start function, an unknown library function with one argument == 0x126F0 is called, and the same function is called from the start function four more times, always with arguments with similar values (0x12718, 0x12738, 0x12758, 0x12760). And in the middle of the program, starting from 0x2490, there are five lines with text messages:
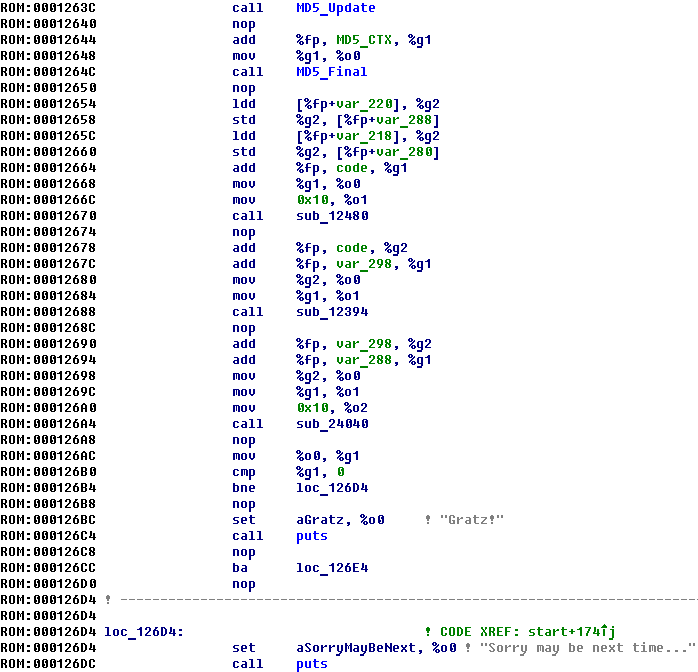
00002490 .ascii "Firmware loaded, sending ok back."<0> 000024B8 .ascii "Failed to retrieve email."<0> 000024D8 .ascii "Failed to retrieve codes."<0> 000024F8 .ascii "Gratz!"<0> 00002500 .ascii "Sorry may be next time..."<0>
Assuming that the load address equals 0x126F0-0x2490 == 0x10260, then all the arguments will indicate the lines when calling the library function, and the unknown function turns out to be the printf function (or puts).
After changing the load base, the code will look something like this:

The value of 0x0BA0BAB0, transmitted to the function sub_12194, can be found in the first part of the task, in the function fire_second_proc, and is compared with what we obtain from read_pipe_u32 (). Thus sub_12194 should be called write_pipe_u32.
Similarly, two calls of the library function sub_24064 are memset (someVar, 0, 0x101) for the email and code, while sub_121BC is read_pipe_str (), reversed write_pipe_str () from the first part.
The first function (at offset 0 or address 0x10260) has typical constants of MD5_Init:

Next to the call to MD5_Init, it is easy to detect the function MD5_Update () and MD5_Final (), preceded by the call to the library strlen ().

Not too many unknown functions are left in the start() function.
The sub_12480 function reverses the byte array of specified length. In fact, it’s memrev, which receives a code array input of 16 bytes.
Obviously, the sub_24040 function checks whether the code is correct. The arguments transfer the calculated value of MD5(email), the array filled in function sub_12394, and the number 16. It could be a call to memcmp!
The real trick is happening in sub_12394. There is almost no hints there, but the algorithm is described by one phrase—the multiplication of binary matrix of the 128 by the binary vector of 128. The matrix is stored in the firmware at 0x240B8.
Thus, the code is correct if MD5(email) == matrix_mul_vector (matrix, code).
Calculating the Key
To find the correct value of the code, you need to solve a system of binary equations described by the matrix, where the right-hand side are the relevant bits of the MD5(email). If you forgot linear algebra: this is easily solved by Gaussian elimination.
If the right-hand side of the key is known (32 hexadecimal characters), we can try to guess the first seven characters so that the CRC32 calculation result was equal to the value found for the key BTEA. There are about 1024 of such values, and they can be quickly obtained by brute-force, or by converting CRC32 and checking valid characters.
Now you need to put everything together and get the key that will pass all the checks and will be recognized as valid by our verifier :)
We were afraid that no one would be able to solve the task from the beginning to the end. Fortunately, Victor Alyushin showed that our fears were groundless. You can find his write-up on the task here. This is the second time Victor Alyushin has won the contest (he was the winner in 2013 as well).
A participant who wished to remain anonymous solved a part of the task and took second place.
Thanks to all participants!